Predicting if there is going to be a Risk Event during a project:
Logistic Regression
Code
from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, confusion_matrix, classification_report# Split the data into features (X) and target (y)X = df[['Duration', 'Budget', 'TeamSize', 'Complexity', 'PriorIssues']]y = df['RiskEvent']# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# Initialize and train the logistic regression modelmodel = LogisticRegression()model.fit(X_train, y_train)# Predict on the test sety_pred = model.predict(X_test)# Evaluate the modelaccuracy = accuracy_score(y_test, y_pred)# conf_matrix = confusion_matrix(y_test, y_pred)class_report = classification_report(y_test, y_pred)print("Logistic Regression Accuracy is:", format(accuracy,".0%"))# print(class_report)
Logistic Regression Accuracy is: 50%
Random Forest
Code
from sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import GridSearchCV# Initialize and train the Random Forest model with hyperparameter tuningparam_grid = {'n_estimators': [100, 200, 300],'max_depth': [None, 10, 20, 30],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]}rf = RandomForestClassifier(random_state=42)grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=3, n_jobs=-1, verbose=0)grid_search.fit(X_train, y_train)# Best parameters from grid searchbest_params = grid_search.best_params_# Train the best modelbest_rf = grid_search.best_estimator_best_rf.fit(X_train, y_train)# Predict on the test sety_pred = best_rf.predict(X_test)# Evaluate the modelaccuracy = accuracy_score(y_test, y_pred)# conf_matrix = confusion_matrix(y_test, y_pred)class_report = classification_report(y_test, y_pred)print("Random Forest Accuracy is:", format(accuracy,".0%"))# print(class_report)# best_params
Random Forest Accuracy is: 50%
Code
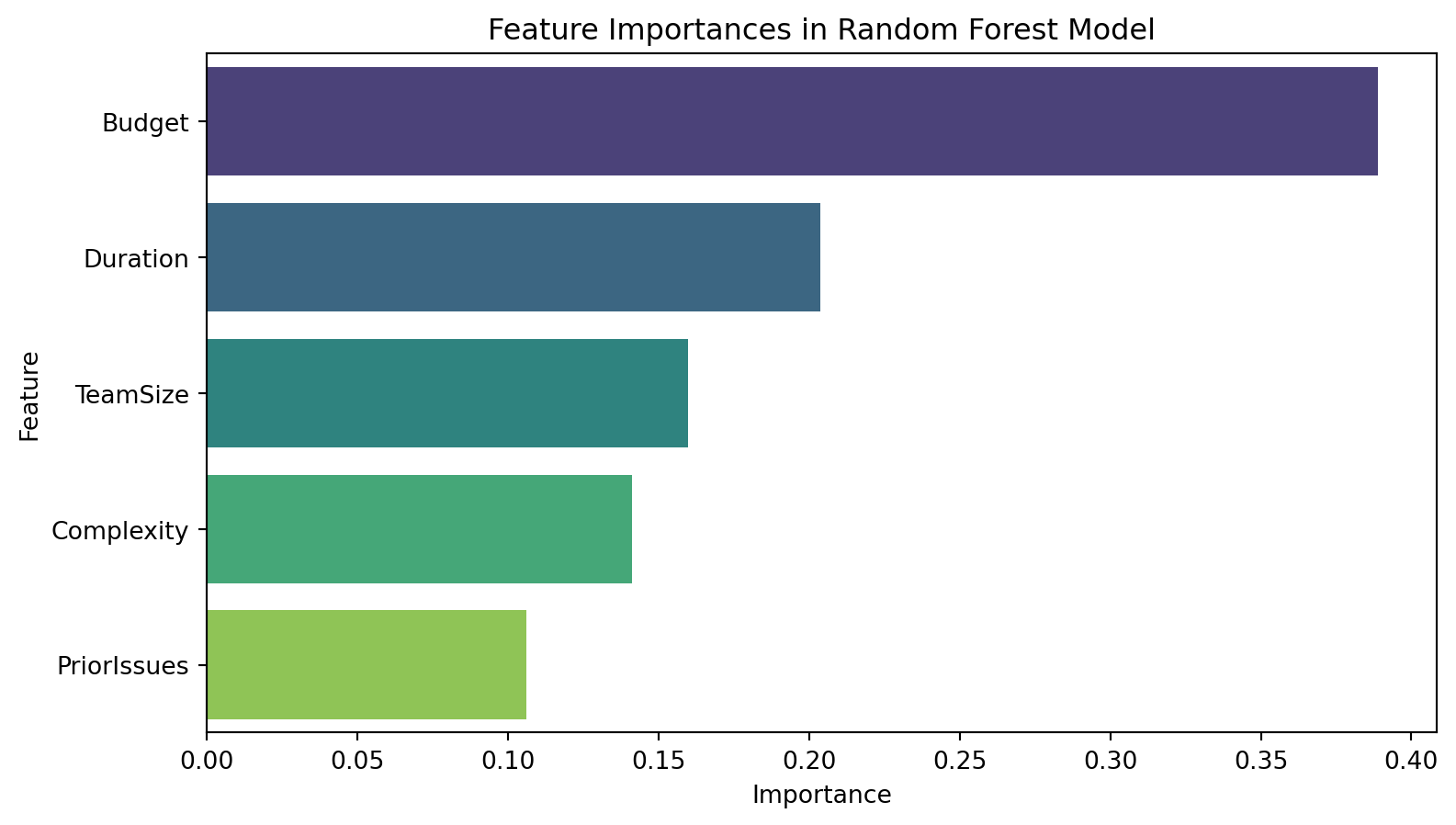
import matplotlib.pyplot as pltimport seaborn as sns# Extract feature importances from the best modelfeature_importances = best_rf.feature_importances_# Create a DataFrame for better visualizationfeatures_df = pd.DataFrame({'Feature': X.columns,'Importance': feature_importances})# Sort the DataFrame by importancefeatures_df = features_df.sort_values(by='Importance', ascending=False)# Display the feature importancesprint("Feature Importances:")print(features_df)# Plotting the feature importancesplt.figure(figsize=(9, 5))sns.barplot(x='Importance', y='Feature', data=features_df, palette='viridis')plt.title('Feature Importances in Random Forest Model')plt.xlabel('Importance')plt.ylabel('Feature')plt.show()