import pandas as pdimport numpy as np# Create dummy datanp.random.seed(42) # For reproducibilitydata = {'ProjectID': range(1, 101),'Duration': np.random.randint(10, 50, size=100),'TeamSize': np.random.randint(5, 20, size=100),'Complexity': np.random.randint(1, 10, size=100),'InitialBudget': np.random.randint(50, 200, size=100),'PriorIssues': np.random.randint(0, 5, size=100),'ProjectType': np.random.choice(['Residential', 'Commercial', 'Industrial'], size=100),'TeamExperience': np.random.randint(1, 15, size=100),'ExternalFactors': np.random.uniform(0.5, 1.5, size=100),'ResourceAvailability': np.random.randint(1, 10, size=100),'ProjectPhase': np.random.choice(['Design', 'Foundation', 'Structure', 'Finishing'], size=100),'ActualCost': np.random.randint(60, 250, size=100)}df = pd.DataFrame(data)# first few rows of the dataframedf.head()
ProjectID
Duration
TeamSize
Complexity
InitialBudget
PriorIssues
ProjectType
TeamExperience
ExternalFactors
ResourceAvailability
ProjectPhase
ActualCost
0
1
48
11
8
117
4
Commercial
5
0.577735
2
Foundation
121
1
2
38
11
9
82
3
Commercial
6
1.474395
3
Design
191
2
3
24
18
4
191
4
Commercial
3
1.486211
3
Foundation
148
3
4
17
12
1
70
3
Commercial
8
1.198162
5
Structure
101
4
5
30
9
1
97
2
Commercial
13
1.036096
5
Structure
148
Data Prep
Code
from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import LabelEncoder# Convert categorical features to numerical valueslabel_encoders = {}categorical_features = ['ProjectType', 'ProjectPhase']for feature in categorical_features: le = LabelEncoder() df[feature] = le.fit_transform(df[feature]) label_encoders[feature] = le# Split the data into features (X) and target (y)X = df.drop(columns=['ProjectID', 'ActualCost'])y = df['ActualCost']# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Model Training
Code
from sklearn.ensemble import RandomForestRegressorfrom sklearn.metrics import mean_squared_error, r2_score# Initialize the RandomForestRegressorrf = RandomForestRegressor(random_state=42)# Train the modelrf.fit(X_train, y_train)# Predict on the test sety_pred = rf.predict(X_test)# Evaluate the modelmse = mean_squared_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)# Output the resultsprint("Mean Squared Error:", mse)print("R^2 Score:", r2)
Mean Squared Error: 3473.57541
R^2 Score: -0.1123097958274566
Hyperparameter Tuning
Code
from sklearn.model_selection import GridSearchCV# Define the parameter gridparam_grid = {'n_estimators': [100, 200, 300],'max_depth': [None, 10, 20, 30],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]}# Initialize GridSearchCV with 3-fold cross-validationgrid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=3, n_jobs=-1, verbose=0)# Fit GridSearchCV to the datagrid_search.fit(X_train, y_train)# Best parameters and model performancebest_params = grid_search.best_params_best_rf = grid_search.best_estimator_# print("Best Parameters from GridSearchCV:")# print(best_params)# Predict on the test set with the best modely_pred_best = best_rf.predict(X_test)# Evaluate the best modelmse_best = mean_squared_error(y_test, y_pred_best)r2_best = r2_score(y_test, y_pred_best)# Output the resultsprint("Mean Squared Error (Best Model):", mse_best)print("R^2 Score (Best Model):", r2_best)
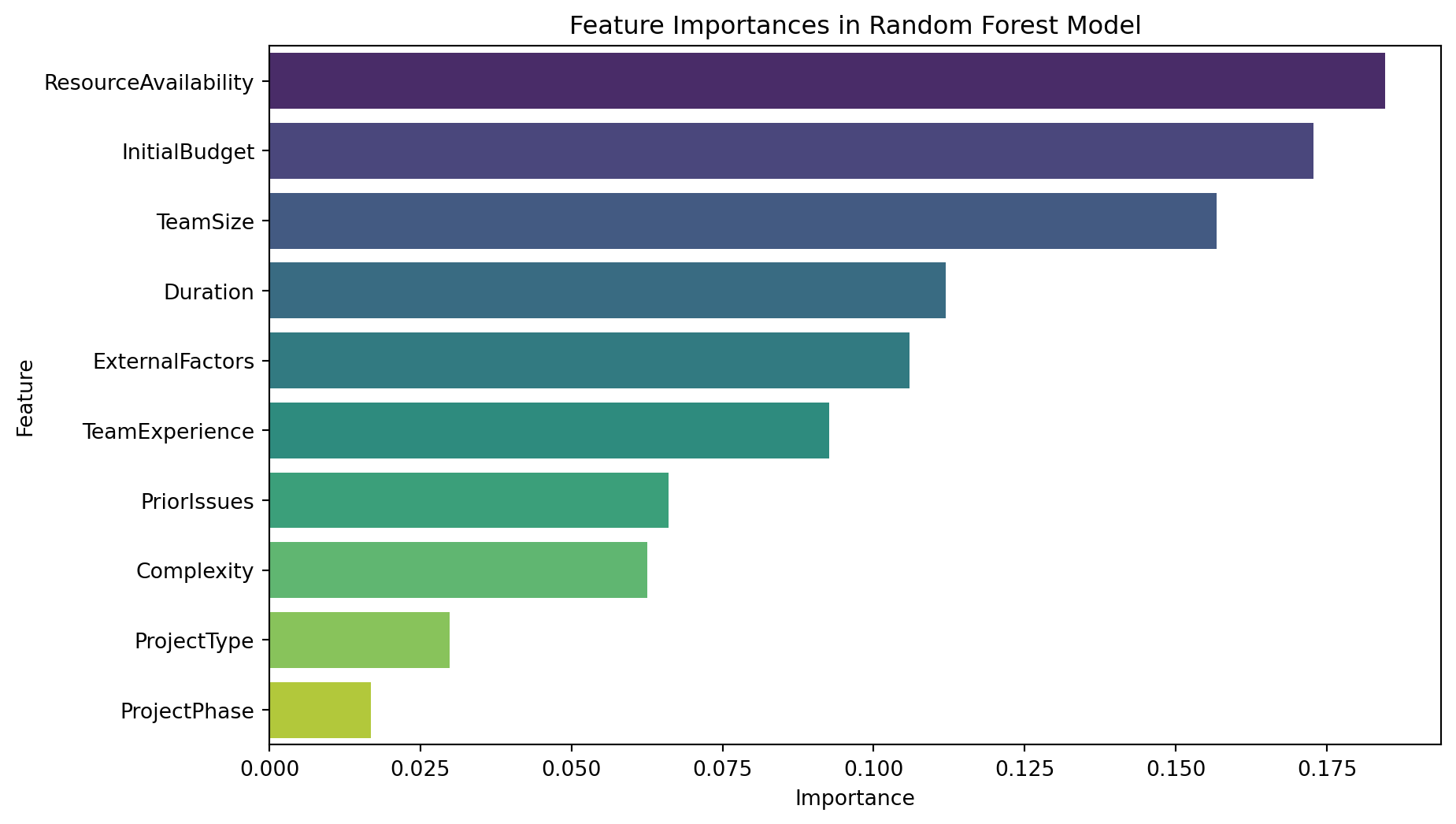
import matplotlib.pyplot as pltimport seaborn as sns# Extract feature importances from the best modelfeature_importances = best_rf.feature_importances_# Create a DataFrame for better visualizationfeatures_df = pd.DataFrame({'Feature': X.columns,'Importance': feature_importances})# Sort the DataFrame by importancefeatures_df = features_df.sort_values(by='Importance', ascending=False)# Display the feature importancesprint("Feature Importances:")print(features_df)# Plotting the feature importancesplt.figure(figsize=(10, 6))sns.barplot(x='Importance', y='Feature', data=features_df, palette='viridis')plt.title('Feature Importances in Random Forest Model')plt.xlabel('Importance')plt.ylabel('Feature')plt.show()